- เข้าร่วม
- 1 มิถุนายน 2011
- ข้อความ
- 15,229
- คะแนนปฏิกิริยา
- 0
- คะแนน
- 36
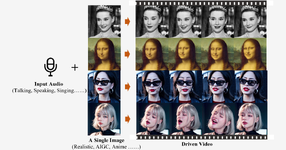
หน่วยงานวิจัย Intelligent Computing ของ Alibaba เผยแพร่เทคโนโลยีโมเดล AI สร้างวิดีโอขึ้นจากรูปภาพและเสียง (image-audio-video) ซึ่งเรียกชื่อโมเดลนี้ว่า EMO
EMO ต้องการอินพุทเพียง รูปภาพพอร์ตเทรตบุคคล กับไฟล์เสียง ก็สามารถสร้างวิดีโอที่เป็นบุคคลนั้นพูดหรือร้องเพลงตามไฟล์เสียงได้ ความยาวสูงสุด 1 นาที 30 วินาที จุดเด่นของ EMO คือการแสดงออกจากสีหน้าของบุคคลก็เป็นไปตามเสียงที่ออกมาด้วย ไม่ใช่แค่การขยับปากเท่านั้น
ตัวอย่างที่นำเสนอ EMO สามารถสร้างวิดีโอให้รูปภาพร้องเพลงได้, ปรับได้ตามภาษาของเพลง, มีการขยับตามจังหวะเพลงที่รวดเร็ว ตัวอย่างหนึ่งที่นำเสนอดูเป็นการข้ามโซนสักหน่อย เพราะใช้ภาพนิ่งจากคลิปผู้หญิงญี่ปุ่นเดินบนถนนที่สร้างจาก Sora โมเดลสร้างวิดีโอของ OpenAI นั่นเอง
รายละเอียดของ EMO สามารถดูเพิ่มเติมได้ที่ GitHub และชมคลิปตัวอย่างได้ท้ายข่าว
ที่มา: Pandaily

Topics:
Alibaba
Artificial Intelligence
อ่านต่อ...
EMO ต้องการอินพุทเพียง รูปภาพพอร์ตเทรตบุคคล กับไฟล์เสียง ก็สามารถสร้างวิดีโอที่เป็นบุคคลนั้นพูดหรือร้องเพลงตามไฟล์เสียงได้ ความยาวสูงสุด 1 นาที 30 วินาที จุดเด่นของ EMO คือการแสดงออกจากสีหน้าของบุคคลก็เป็นไปตามเสียงที่ออกมาด้วย ไม่ใช่แค่การขยับปากเท่านั้น
ตัวอย่างที่นำเสนอ EMO สามารถสร้างวิดีโอให้รูปภาพร้องเพลงได้, ปรับได้ตามภาษาของเพลง, มีการขยับตามจังหวะเพลงที่รวดเร็ว ตัวอย่างหนึ่งที่นำเสนอดูเป็นการข้ามโซนสักหน่อย เพราะใช้ภาพนิ่งจากคลิปผู้หญิงญี่ปุ่นเดินบนถนนที่สร้างจาก Sora โมเดลสร้างวิดีโอของ OpenAI นั่นเอง
รายละเอียดของ EMO สามารถดูเพิ่มเติมได้ที่ GitHub และชมคลิปตัวอย่างได้ท้ายข่าว
ที่มา: Pandaily
Topics:
Alibaba
Artificial Intelligence
อ่านต่อ...
ไฟล์แนบ